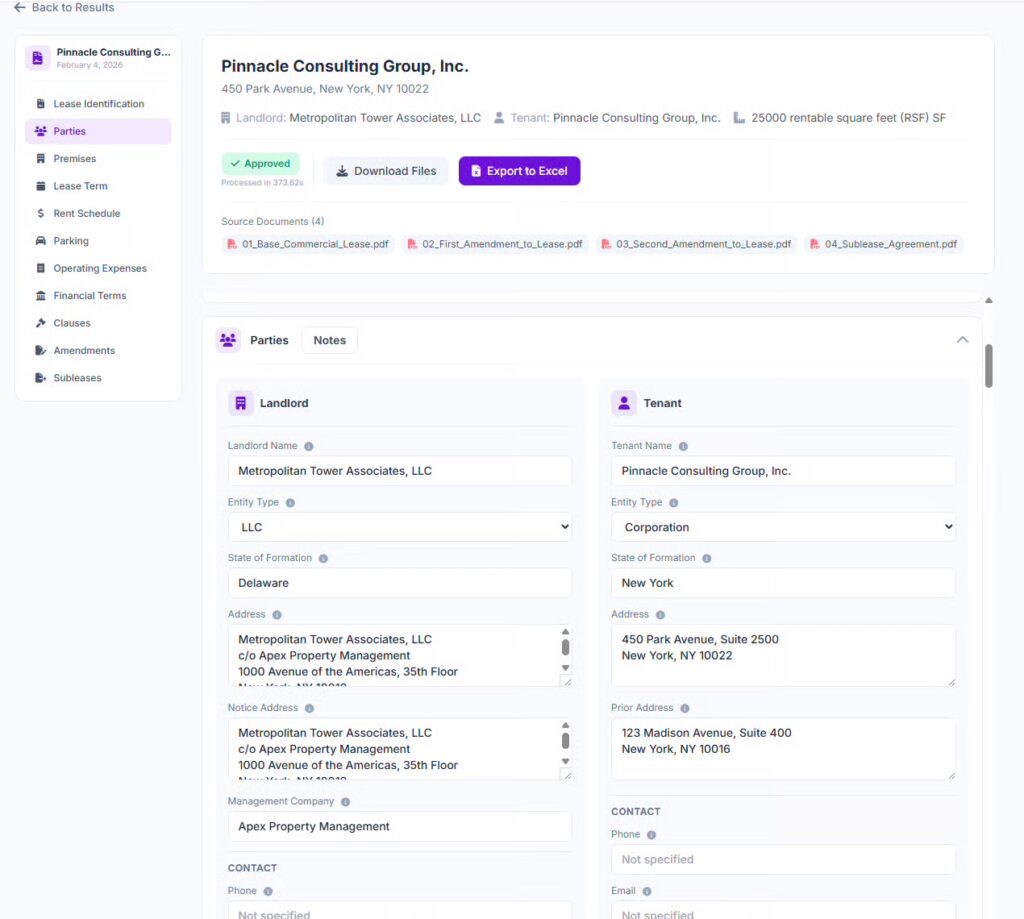
Why We Spent 7 Months on a Problem Others Had Already “Solved”
Seven months ago, we started exploring AI lease abstraction after being approached by an asset manager who had been doing the process manually, trying to abstract hundreds of leases a month.
They were already using widely available tools like Claude and ChatGPT, with fairly advanced setups, and were getting to around 60–70% accuracy on a lease. They came to us wondering if there was a way to push that to 90–100% with a more streamlined process.
We were upfront with them. There were already well-funded competitors in the market that had been focused specifically on this problem for years. And while those tools were good, the feedback was the same: accuracy still wasn’t high enough to eliminate the manual review step. You were still paying someone to go back through every lease.
We told them honestly, no matter what we built, they’d probably still end up with some form of human-in-the-loop review. But the problem was interesting enough that we wanted to try anyway.
What intrigued us most was that even the most advanced models struggled with lease abstraction across a full document, despite being really accurate on single files. These models are genuinely good at parsing PDFs and extracting structured data, so why was lease abstraction still falling apart? That curiosity is what pulled us in.
We tried a few different approaches, kept iterating on the methodology, and after seven months, we believe we’ve landed on a pattern that gets accuracy significantly higher than what we were seeing before.
The core of it is something we’re calling programmatic decomposition. Instead of sending a large lease file to a model and hoping it figures everything out in one shot, we break the file into small, atomic pieces, classify each piece, then use multiple models to individually solve smaller, targeted questions on the data. The answers are then programmatically reassembled, with judging evals running back up the chain to produce one final output.
The result: we’re now able to extract up to 900 data points from a single lease. Is it 100% accurate? No, there are still items that come back wrong. But through our iterations, we’ve also built in the ability to show exactly where in the lease each data point was pulled from, which model was used, and the reasoning behind it. That makes human review, when it’s still needed, significantly faster and easier.
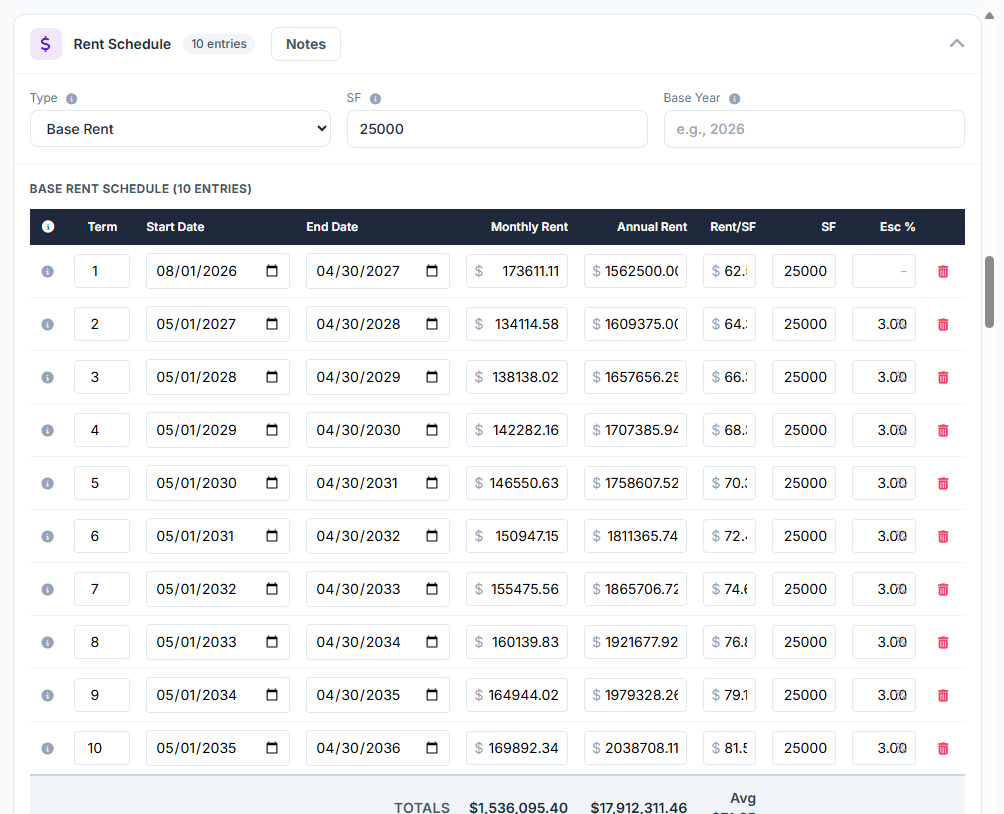
We haven’t eliminated the human step entirely. But we’ve meaningfully reduced the time it takes, and we’re still layering in features to make the process smoother, including a double-review workflow for teams that need it.
The real value of these seven months, though? It taught us how to programmatically work with AI APIs to solve complex problems through structured workflows, and more importantly, how to actually deploy evals and judging. Most people skip that part when they’re building AI solutions, and it’s where a lot of the accuracy gets left on the table.
Some of this work may still be throwaway in the long run. But as a way to deeply learn how these models work, and where they break down, it was absolutely worth it.
Interested in trying out the tool, send me a note on LinkedIn.